
SQL(结构化查询语言)是一种设计用于检索和操作数据的数据库。它是美国国家标准协会(ANSI)的标准。此语言用于执行选择,更新,删除和插入等数据任务。 表是在具有列和行的模型中设计的数据集合。在表中,指定了列数,称为字段,但未定义行数,称为记录。 数据库是有序形式的一组信息,用于访问,存储和
SQL(结构化查询语言)是一种设计用于检索和操作数据的数据库。它是美国国家标准协会(ANSI)的标准。
此语言用于执行选择,更新,删除和插入等数据任务。
表是在具有列和行的模型中设计的数据集合。在表中,指定了列数,称为字段,但未定义行数,称为记录。 数据库是有序形式的一组信息,用于访问,存储和检索数据。 DBMS是一个控制数据维护和使用的程序。
它被认为是管理数据的文件管理器。有四种类型的DBMS: 最有用的DBMS是Relational DBMS。它为数据提供了一个关系运算符。
SQL命令分为以下类型: 它包含来自一个或多个表的行和列,可以定义为虚拟表。它消耗的内存较少。 句法: Join用于从相关的行和列中检索数据。
它在两个或多个表之间工作,并且它从两个表返回至少一个匹配。 连接类型是: 数据库查询是数据库表中的数据请求。查询可以是选择查询或任何其他类型的查询。
子查询是查询的一部分。外部查询已知主查询,内部查询识别子查询。始终首先执行子查询,并将结果传递给主查询。 Autoincrement是一个关键字,用于在表中插入新记录时生成数字。
它可用于设置表中数据类型的限制。在创建或更新表语句时,可以使用约束。一些限制是: SQL中有不同类型的键: 规范化是一种设计技术,它以减少数据依赖性的方式排列表。它将表分成小模块并按关系链接。
非规范化是一种优化方法,我们将多余的数据增加到表中,并在规范化后应用。 存储过程是一组SQL语句,用作访问数据库的函数。为了减少网络流量并提高性能,我们使用存储过程。 句法: 索引用于加速查询的性能。
它可以更快地从表中检索数据。可以在一组列上创建索引。 聚簇索引 - 它有助于轻松检索数据,并且只有一个聚簇索引与一个表一起分配。
它会更改记录在数据库中的保存方式。 非聚集索引 - 与聚簇索引相比,非聚簇索引很慢。并且在非集群索引的情况下,该表可以具有多个索引。
它为表创建一个对象,该表是搜索后指向表的一个点。 触发器 被 用来执行对表中的特定动作,诸如插入,更新或删除 。它是一种 存储过程 。动作和事件是触发器的主要组成部分。
执行Action时,事件响应该操作而出现。 通常,这些属性称为ACID。它们有助于数据库事务。
A tomicity -在一个事务中连接两个或更多个单独的数据块,或者所有的块都致力于,或者一个都不。 C onsistency - 事务或者生成新的有效数据状态,或者如果发生任何失望,则在事务启动之前将所有数据返回到其状态。 I solation - 正在进行且尚未提交的事务必须继续与任何其他操作隔离。 D urability -在此操作中,系统保存提交的数据,每当事件发生故障和系统启动后,所有的数据是可用的正确的位置。
SQL语句分为几类: 它被定义为通过为查询提供条件来设置结果集的限制。他们从整个记录中过滤掉一些行。 一些SQL CLAUSES是WHERE和HAVING。
它是一个返回单个值的数学函数。 SQL中的聚合函数是: 为了操作。
SQL数据库面试题 急急急
a)select pname as '商品名',avg(qty) as 平均销售量 from s,p,m where m.city='上海' and s.mno=m.mno and p.pno=s.pno,select p.Pno,p.pname,sum(s.qty)from s left join p on s.pno=p.pno left join m on p.Mno=m.Mnowhere m.city='上海市'group by p.Pno,p.pname,p.city,p.colorb)、先删除Sale表的外键PNO,再删除gds表。c)联系:视图(view)是在基本表之上建立的表,它的结构(即所定义的列)和内容(即所有数据行)都来自基本表,它依据基本表存在而存在。
一个视图可以对应一个基本表,也可以对应多个基本表。
视图是基本表的抽象和在逻辑意义上建立的新关系区别:1、视图是已经编译好的sql语句。而表不是 2、视图没有实际的物理记录。 3、表是内容,视图是窗口 4、表只用物理空间而视图不占用物理空间,视图只是逻辑概念的存在,表可以及时四对它进行修改,但视图只能有创建的语句来修改 5、表是内模式,视图是外模式 6、视图是查看数据表的一种方法,可以查询数据表中某些字段构成的数据,只是一些SQL语句的集合。
从安全的角度说,视图可以不给用户接触数据表,从而不知道表结构。 7、表属于全局模式中的表,是实表;视图属于局部模式的表,是虚表。 8、视图的建立和删除只影响视图本身,不影响对应的基本表。
sql面试题
1、忍不住想说一句,因为第一题中的字段类型是 【日期型】,而各种数据库操作日期型数据有不同的方法,没有一种共通的方法,所以脱离了数据库而言没有一种共通的sql。2、select ID,NAME,ADDRESS,PHONE,LOGDATE from T where ID in( select ID from T group by NAME having count(*)>1) order by NAME;3、delete from T where ID not in (select min(id) from T group by name);4、update T set T.ADDRESS=(select E.ADDRESS from E where E.NAME=T.NAME), T.PHONE=(select E.PHONE from E where E.NAME=T.NAME);5、这个不同的数据库也有不同的处理方法,不能脱离数据库谈了。
如:SqlServer或者access可以使用 top oracle可以使用 rownum 等---以上,希望对你有所帮助。
SQL语句面试题
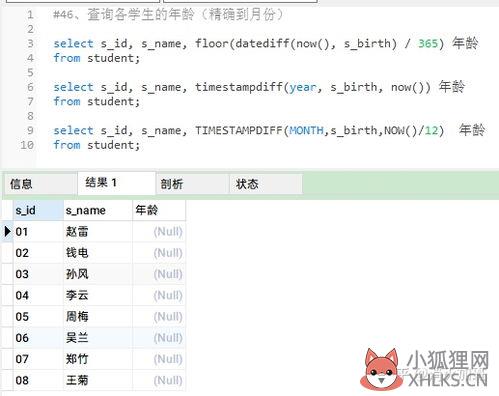
恩,通过自定义函数吧。







